
How Machine Learning Will Support the Data Strategy


24 February 2021
By Lambert Hogenhout, Chief of Data, Analytics and Innovation, OICT
Collecting data, organizing it, and sharing it is useful. Ultimately, however, the aim is to create business value. We want to turn data into insights that result in productivity gains, better decisions and/or faster response.
There are multiple ways to do that — from simple dashboards to interactive data visualizations, deeper analysis with statistical methods, or natural language processing — and new technologies keep leading to more sophisticated techniques. One area that has been at the center of academic and commercial attention recently is Machine Learning (ML).
What is Machine Learning?
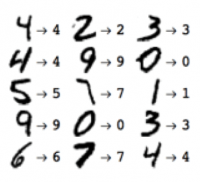 Traditional computer applications consist of code specifying exactly what the computer should do in any possible situation, for each type of input. In contrast, ML is an approach in which the computer is not explicitly told what to do but learns from examples or from feedback.
Traditional computer applications consist of code specifying exactly what the computer should do in any possible situation, for each type of input. In contrast, ML is an approach in which the computer is not explicitly told what to do but learns from examples or from feedback.
An early use of ML was recognizing numbers written on postal mail, when envelopes with hand-written addresses was common. Everyone writes numbers slightly differently, but after seeing thousands of examples of handwritten numbers, computers using ML were able to learn to recognize the numbers with almost perfect accuracy.
ML has progressed greatly since then. In fact, there are many tasks at which it is far better than humans – from analyzing x-rays for potential signs of cancer, to catching fraudulent credit card transactions as they happen. Furthermore, several companies are working on self-driving cars that have learned from millions of previously driven miles. This too is ML.
Imitating the Brain
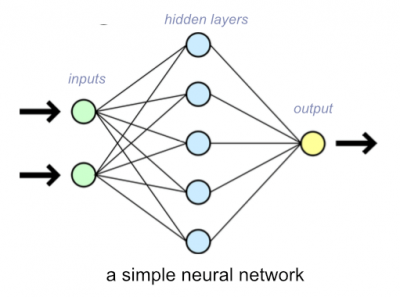
One ML technique is called Neural Networks. It takes inspiration from neurons in the human brain in that it consists of digital neurons that trigger responses in one another and create bonds. For example, after seeing examples of the number 6, the computer will discover that there seems to be a circular shape at the bottom of the 6, so in the neural net, the connection between the node that represents 6 and the node that represents a circular shape will be strengthened. Neural networks work in many layers, for instance moving from light to dark areas, to detecting the edges of a shape, to detecting shapes like circles or diagonal lines, to identifying numbers. These intermediate layers are discovered and automatically created by the computer itself. This also means that, in large neural networks, humans do not necessarily have an idea about the meaning of concepts in these hidden layers. This also means that, in large neural networks, humans do not necessarily have an idea about the meaning of concepts in these hidden layers, and this can raise ethical issues if we are not careful.
Applications for the UN
ML is particularly useful in cases where systems are so complex that we don't have a precise model to describe their dynamics because there are too many variables at play, such as ecosystems in oceans. ML can also be well suited for environments that are subject to constant change, like social dynamics in cities and countries, and, therefore, need adaptive models that learn as they go.
At the United Nations, as we deal with a wide variety of complex challenges in a world that is constantly in flux, we stand to benefit significantly from ML.
Indeed, ML has been used in practical applications for social good: the Mila Project in Canada uses it to analyze (and visualize) climate change the NGO Rainforest Connection uses is in its efforts to protect forests, and the Peace Parks foundation uses it to tackle rhino poaching. Other examples include early detection of crop damage from aerial photography, combating money-laundering, and human trafficking. Automatic translation (of human language) is another area that ML has helped progress very rapidly, and that should be of great interest to the UN.
Data Plays a Central Role
Let us remember that data is the essential fuel for ML. To achieve success in ML, we need data that ideally has been classified or tagged in some way. In the past, ML typically needed very large amounts of data ("Big Data") from which to learn. Today, new techniques exist that allow learning from much smaller data sets. For instance, a technique called Transfer Learning allows us to transfer skills obtained in one context to another context, so less training is needed in the new ML model. You might compare it to benefiting from your snowboarding skills when learning windsurfing. But the need for quality data remains, because if we train our ML models with faulty data, it will lead to incorrect or possibly biased results (“garbage in - garbage out”).
Looking Ahead
To achieve the vision of the Secretary-General's Data Strategy we need to collect and organize a good base of quality data. With such data, ML can provide us with a wide range of applications to gain new insights rapidly, as well as to automate time-consuming tasks. For example, our team in OICT recently built an ML-based solution for the Office for Disaster Risk Reduction (UNDRR) to automatically classify documents, saving hundreds of hours of staff time. We have also used ML to build the UN Secretariat’s chat-bot, Alba.
This is just the beginning — ML will significantly change the field of data and analytics in the coming years and OICT is excited to be leading in this space.
Note: The views expressed herein are those of the author and do not necessarily reflect the views of the United Nations.